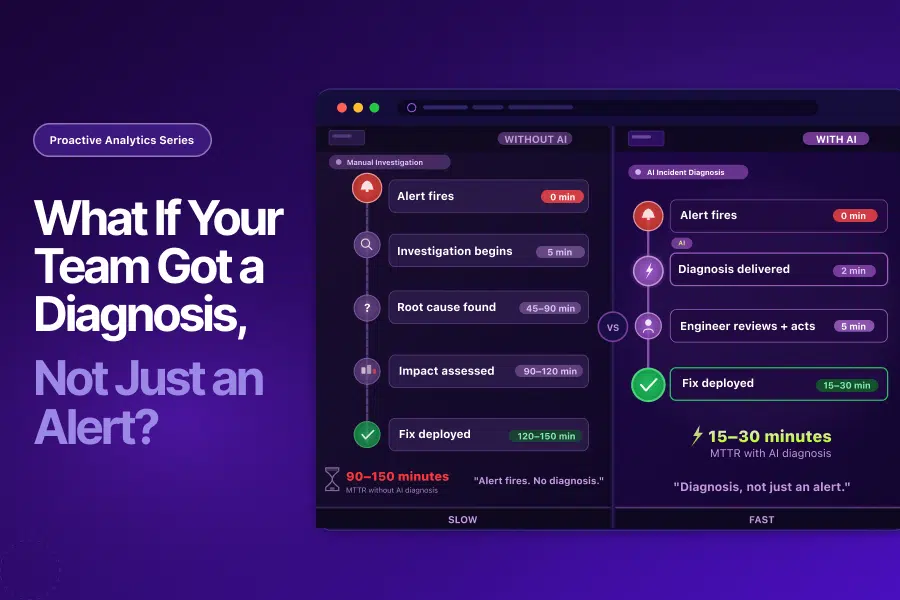
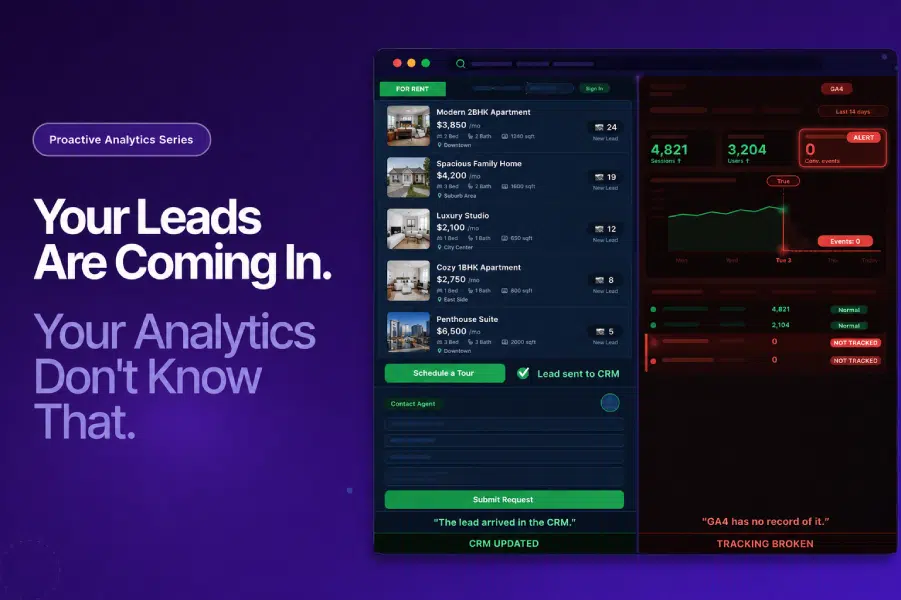
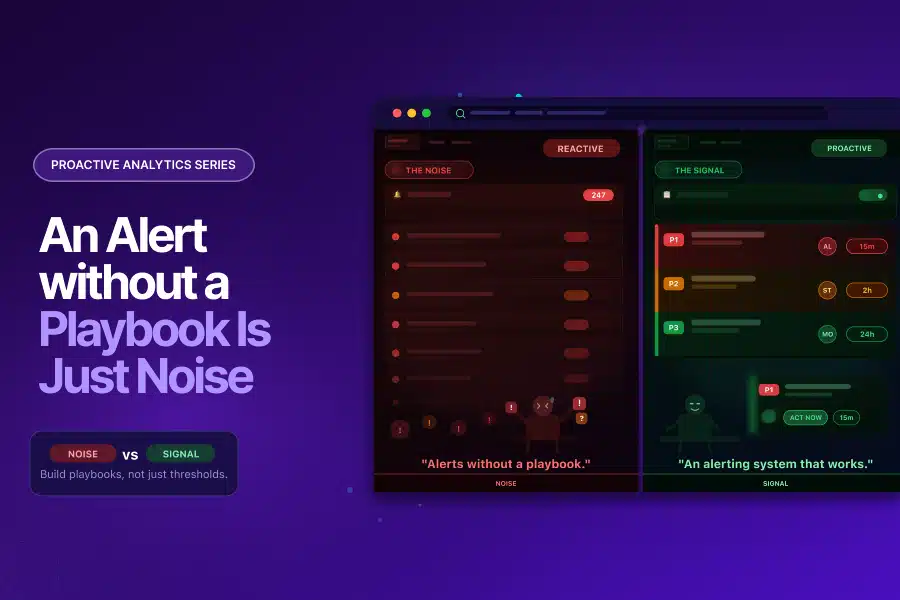
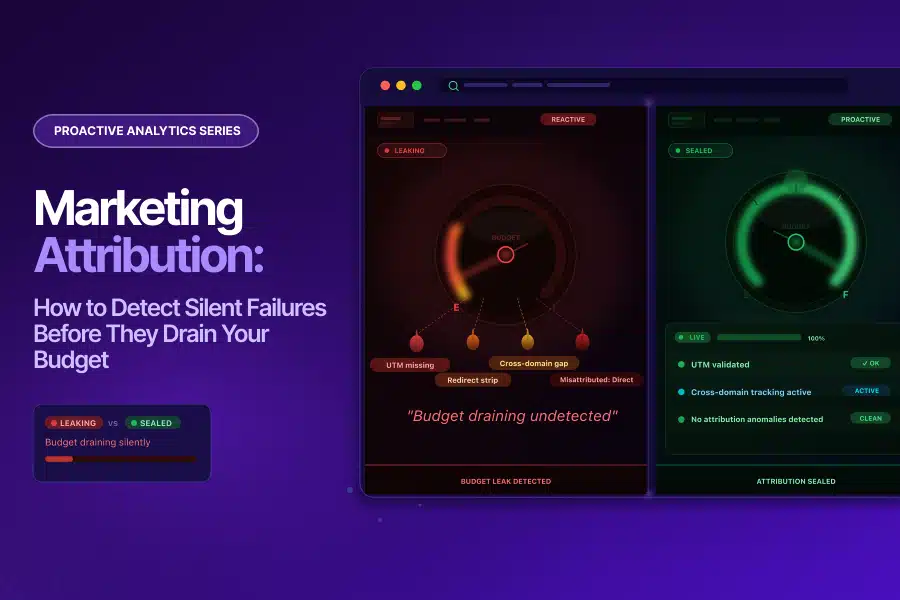
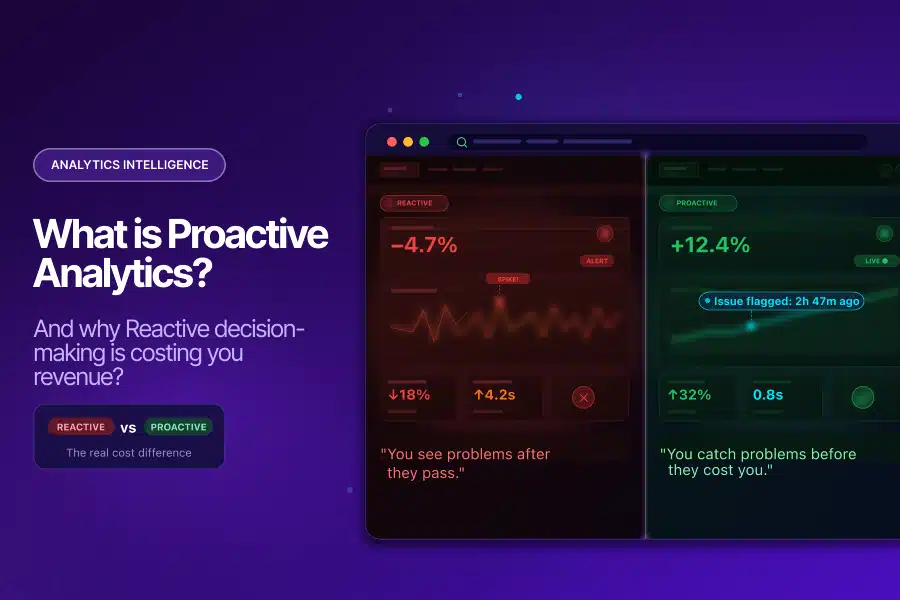
Streamlining the User Journey: How GTM Consolidation Helped ICICI Lombard Enhance Website Performance and Reduce Container Size