

When AI Makes Bad Data More Dangerous: The Case for Data Quality AI Analytics
Every blog in this Proactive Analytics series has built toward this point.
We’ve covered why reactive monitoring fails businesses in Proactive Analytics, how to extend your detection layer in Anomaly Detection in GA4, and how to build alerts that actually drive action in Building an Analytics Alerting System. The thread running through all of it has been simple: bad data caught late costs far more than bad data caught early.
But there’s a new dimension to that argument now. One that makes data quality AI analytics not just a best practice but a business survival question.
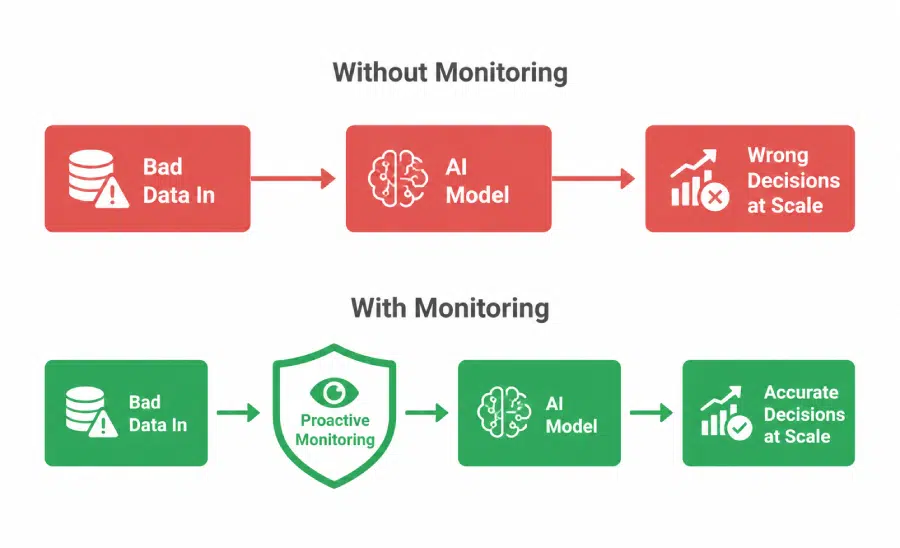
AI doesn’t catch bad data. It amplifies it.
AI Is Already in Production. And It’s Hungry for Your Data.
Let’s be clear about where things stand. Data quality AI analytics isn’t a future problem to prepare for. It’s a present one, happening right now, inside organizations that have already deployed AI models in marketing and analytics.
Gartner’s April 2026 research surveyed 353 data and analytics leaders and found something telling:
- Organizations with successful AI initiatives invest up to 4x more in data quality, governance, and AI-ready foundations than those with poor outcomes
- Only 39% of technology leaders are confident their current AI investments will deliver a positive financial impact
That gap between investment and confidence isn’t a technology problem. It keeps coming back to the same root cause: the data feeding these AI models isn’t ready for them. Data quality AI analytics is where the gap lives, and most organizations haven’t closed it yet.
And what exactly is that data? It’s your GA4 data. Your attribution data. Your campaign performance data. The same data this series has shown can be quietly corrupted by GTM misconfigurations, UTM parameters stripped in redirects, cross-domain tracking gaps, and parameter-level schema mismatches that nobody catches for weeks.
When that data lived only in reports, the damage was contained. A bad report informed a bad decision. When that same data feeds an AI model, one bad input becomes thousands of bad outputs.
Here’s What Nobody Tells You About AI and Data Quality
Most conversations about AI failure focus on the model. Wrong architecture, wrong training approach, not enough data. That’s rarely where the real problem is, and it’s why data quality AI analytics deserves its own conversation entirely.
Think about what an AI model actually does.
- It takes what you give it, finds patterns in it, and applies those patterns to new situations.
- It doesn’t have intuition.
- It can’t look at a number and think “that seems off.”
A human analyst reviewing a GA4 report might notice that revenue looks inflated, trace it back upstream, and find a double-firing purchase event. An AI model won’t. It’ll learn that inflated revenue is normal, build its patterns around that assumption, and confidently produce outputs based on it.
That’s not a flaw in the AI. It’s working exactly as designed. The failure is upstream, in the data quality layer that was never built to support it.
Here’s what poor data quality AI analytics looks like in practice:
When predictive models train on bad data, they predict badly at scale.
Say a purchase propensity model trains on GA4 data where conversion events were double-firing for three weeks. It learns those inflated patterns as its baseline. The high-value audiences it identifies are built on fictional behaviour. Campaigns targeting them underperform, and even after the data issue is fixed, the model needs time to unlearn what it was taught.
When attribution models get corrupted channel data, they misallocate budget systematically.
An AI-driven attribution model fed two months of data where paid social conversions were misattributing to direct traffic will learn to undervalue paid social. Every budget recommendation it produces carries that bias forward. The error doesn’t stay static, it compounds across every campaign cycle.
When personalisation engines get the wrong behavioural signals, they deliver the wrong experiences.
A personalisation model running on product interaction data corrupted by parameter schema errors optimises for signals that were never accurate. Users get recommendations built on behaviour that was never correctly recorded. Engagement drops. The team looks at the model, not the data.
In each of these scenarios, the AI model isn’t making mistakes. It’s faithfully processing exactly what it was given. The problem was never the model. It was the data quality AI analytics foundation that was never properly built beneath it.
What the Numbers Say
Gartner has been direct about this, and the research comes straight from their own published reports, not interpretation.
Gartner’s February 2025 survey of 248 data management leaders found:
- 63% of organizations either don’t have or aren’t sure they have the right data management practices for AI
- Through 2026, Gartner predicts organizations will abandon 60% of AI projects that aren’t supported by AI-ready data
The 2026 Gartner Magic Quadrant for Augmented Data Quality Solutions puts a forward-looking number on the response: by 2027, 70% of organizations will adopt modern data quality solutions to support their AI adoption. The market is moving toward data quality AI analytics investment because it has to.
Most recently, Gartner’s May 2026 research predicted that 40% of organizations deploying AI will implement dedicated observability tools by 2028 to monitor model performance, bias, and outputs continuously. Gartner’s recommendation is explicit: mandatory monitoring policies for all production deployments, with continuous tracking of data quality metrics.
Meanwhile, poor data quality already costs the average organization $12.9 million annually according to Gartner. That’s before you factor in AI. Once AI is in the mix, decisions made on bad data happen faster, reach further, and carry more confidence behind them. The cost of weak data quality AI analytics doesn’t stay the same. It scales.
What “AI-Ready Data” Actually Means in Practice
Gartner defines AI-ready data as data that is aligned to specific use cases, actively governed at the asset level, supported by automated pipelines with quality gates, and continuously quality-assured.
That last word, “continuously,” is where most data quality AI analytics setups break down. Traditional data management works in cycles: quarterly audits, annual governance reviews, periodic pipeline checks. AI models in production need data quality signals measured in hours, not quarters. That mismatch is exactly where most data quality AI analytics failures originate.
The proactive monitoring capabilities covered across this series address each layer of that gap directly:
- Continuous parameter validation makes sure what enters GA4 is accurate before it becomes a training signal for anything downstream. A purchase event passing the wrong currency code doesn’t just corrupt one report. It corrupts every model trained on that data, potentially for months. This is data quality AI analytics at the collection layer.
- Anomaly detection on AI input metrics watches for shifts in the data patterns that feed your models. When paid social’s share of attribution credit drops sharply without a corresponding spend change, that’s not just an attribution problem. It’s a signal that your attribution model’s training data is being distorted. Catching it in hours rather than weeks stops the model from learning the wrong lesson.
- GTM health monitoring protects the collection layer everything else depends on. Tatvic’s anomaly detection solution works at this layer, making sure the events and parameters feeding your analytics and AI tools are collected accurately and consistently.
- A response playbook with defined SLAs closes the loop. Detecting a data quality issue and not acting on it before the next model training cycle is the same as not detecting it at all. Good data quality AI analytics means the alert triggers a response fast enough to matter.
Building the Stack That Protects Your AI Investment
Getting data quality AI analytics right isn’t a single project. It’s a sequence of capabilities, each protecting the layers above it. The order matters.
Start with data collection integrity.
Everything else sits on top of this. Validate event parameters, monitor GTM health continuously, and run automated sanity checks on what enters GA4. If this layer is unreliable, your entire data quality AI analytics foundation is compromised before any model sees it.
Add anomaly detection on your model input data specifically.
Don’t just monitor headline KPIs. Identify the exact metrics, dimensions, and attribution signals that your AI models use as inputs and set intelligent monitoring on those. A shift in these signals that goes undetected becomes a corrupted training dataset. It’s that straightforward.
Build alert-to-action workflows for data quality issues.
When something breaks, the response has to happen before the next model training cycle. Define who owns data quality alerts that affect AI inputs, what the SLA is, and how it escalates. If that’s not documented before the alert fires, it’ll be negotiated under pressure after the fact.
Reconcile AI outputs against ground truth regularly.
Once a month at minimum, compare what your AI models are recommending against a verified external source: CRM data, finance records, e-commerce backend figures. This is how you catch model drift before it compounds into months of systematically wrong budget decisions.
Is Your Data Actually AI-Ready?
Before the next AI analytics investment gets signed off, it’s worth being honest about what your data quality AI analytics foundation actually looks like:
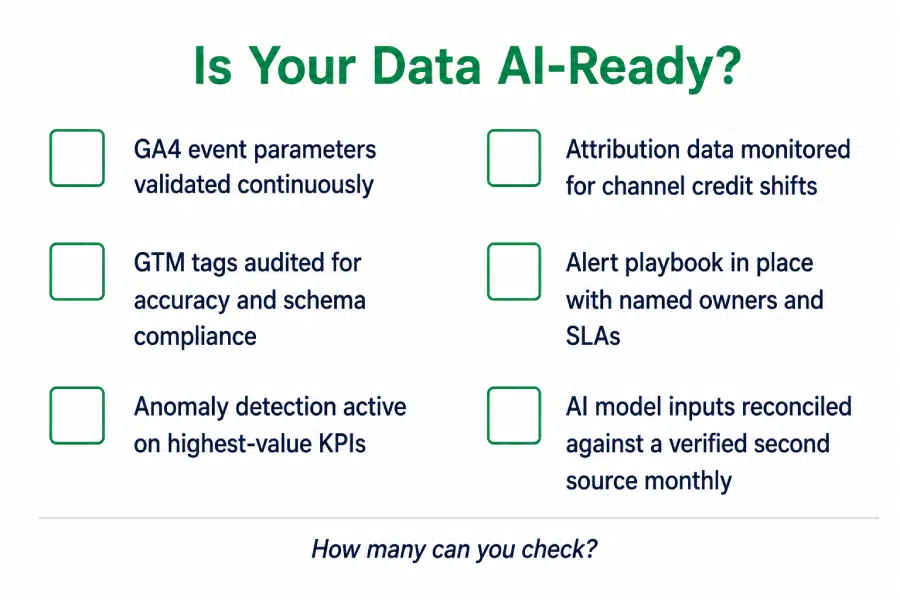 Two or more gaps here means your AI investment is building on a data quality AI analytics foundation that wasn’t designed to support it. The models might be excellent. The underlying problem is upstream.
Two or more gaps here means your AI investment is building on a data quality AI analytics foundation that wasn’t designed to support it. The models might be excellent. The underlying problem is upstream.
The Takeaway
AI doesn’t make data quality less important. It makes it the thing everything else depends on.
Every capability in this Proactive Analytics series, detecting anomalies, validating data at the collection layer, monitoring attribution patterns, building alert playbooks, now has a second job. It’s not just protecting your reports. It’s protecting the integrity of every AI model that learns from your data.
The organizations that will get the most out of AI analytics over the next two years won’t necessarily have the most sophisticated models. They’ll have the most reliable data quality AI analytics foundation feeding them. That’s what separates AI that earns trust from AI that quietly misleads.
Proactive analytics isn’t just a measurement best practice anymore. In an AI-enabled business, strong data quality AI analytics is the foundation every intelligent decision runs on.
Investing in AI analytics and want to make sure your data is actually ready for it? Tatvic’s team can assess your current data quality setup across GA4, GTM, attribution, and monitoring layers and identify exactly where the gaps are. Schedule a call with Tatvic’s experts today.

