
In my upcoming three blogs, I am going to discuss about how Product managers, Data analyst and Data scientists can develop model for the prediction of the transactional product revenue on the basis of user actions like total numbers of time product added to the cart, total numbers of time product added to the cart, total numbers of page view of product and more. Product managers and data scientists can use linear regression tool for model based predictive analysis on business data here. We will apply regression learning on product transactional data for defining most effective variables that can impact on product transactional revenue. In this blog, I will discuss about how can we develop prediction model on GA dataset and what are the summary statistics of the model. First, we will see how data analyst can get transaction related dataset from source (Google Analytics) for predictive analysis of product revenue.
Business Dataset:
For business analytics, we require set of product purchase historical data on which we can perform analysis operations. We use Google Analytics for capturing datasets like product name, product SKU for purchase items, numbers of instances removed from the cart, total numbers of product page view, item revenue and more.
After capturing data from Google Analytics, we store it on our Mongo Instance on Amazon server. With RMongo Package we can load datasets in R-studio (is free and open source integrated development environment (IDE) for R) or can also use r-google-analytics for doing the same.
As we know, business data can be either numerical or categorical. Suppose, if we take product revenue and number of product page views then they will be considered as Numerical Data. But if we take product-name and country-name then they will be considered as Categorical Data.
We have available extracted Google Analytics dataset which looks like below that we used for Shopping cart analysis in last post.
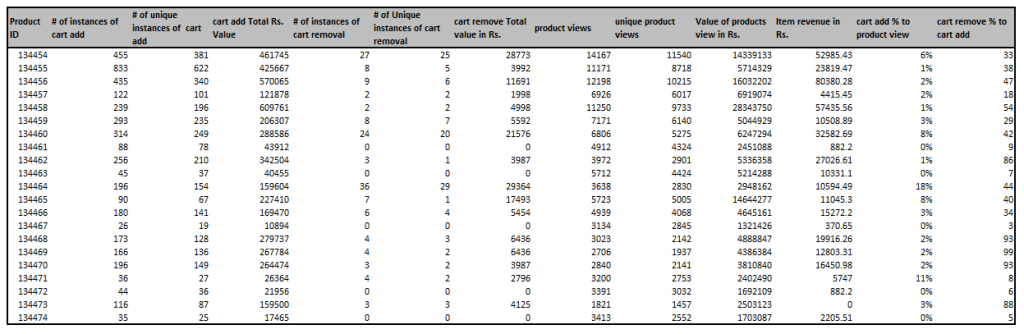
[click on image for full-size image]
We have collected list of necessary variables from available Google analytics dataset for predictive model development, which are
- yitemrevenue – Item Revenue at Rs
- xcartadd – Numbers of instance added to cart
- xcartuniqadd – Numbers of unique instance added to cart
- xcartaddtotalrs –Total Rs value of products after they are added to cart
- xcartremove- Numbers of instances removed from cart
- xcardtremovetotal – Total numbers of instances removed from cart
- xcardtremovetotalrs – Total Rs after numbers of instances removed from cart
- xproductviews – Numbers of page views
- xuniqprodview – Numbers of uniqe product views
- xprodviewinrs – Rs at total numbers of page views
After collecting the necessary data, we are ready to develop predictive model in R. Here, we require a response variable and explanatory variables for regression modeling. The element which is predicted is called the response variable. The variables by which we are going to predict the response variable are called the explanatory variables. In the next part, we will develop model with regression tool.
Model development in R:
Since we are trying to describe the relationship between product revenue and user behavior, we will develop a regression model with product revenue as the response variable and the rest are explanatory variables. With this relationship, we can predict transactional product revenue. We have separated the dataset in response variable and explanatory variables as:
Response variable:
- yitemrevenue – Item Revenue at Rs
Explanatory variables:
- xcartadd – Numbers of instance added to cart
- xcartuniqadd – Numbers of unique instance added to cart
- xcartaddtotalrs –Total Rs after instances added to cart
- xcartremove- Numbers of instances removed from cart
- xcardtremovetotal – Total numbers of instances removed from cart
- xcardtremovetotalrs – Total Rs after numbers of instances removed from cart
- xproductviews – Numbers of page views
- xuniqprodview – Numbers of uniqe product views
- xprodviewinrs – Rs at total numbers of page views
Now, we can assume that this dataset is ready for preparing the linear regression model. In R, we can use lm() function for implementation of linear model with following syntax.
> fit <- lm(formula,data)
Here, (fit) object is linear model and (data) is data object to be applied in the model. A model can be developed using the following code
> model <- lm(formula=yitemrevenue ~ xcartadd + xcartuniqadd + xcartaddtotalrs + xcartremove + xcardtremovetotal + xcardtremovetotalrs + xproductviews + xuniqprodview + xprodviewinrs , data = data)
Here, model object is regression model in which we are interested in. We have implemented it by above formula, (~ ) sign separates the response variables with explanatory variable. Variable on the left side of the sign is the response variable and on the right are explanatory variables. We can check summary statistics of the model with the summary function in R. With summary statistics, we can measure the prediction accuracy of model. Here is summary of our linear model
> summary(model)
Call:
lm(formula = yitemrevenue ~ xcartadd + xcartuniqadd + xcartaddtotalrs +
xcartremove + xcardtremovetotal + xcardtremovetotalrs + xproductviews +
xuniqprodview + xprodviewinrs)
Residuals:
Min 1Q Median 3Q Max
-22489 -143 -58 -34 37838
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.544e+01 2.325e+01 1.524 0.127464
xcartadd -5.209e+01 1.343e+01 -3.878 0.000107 ***
xcartuniqadd 4.220e+01 1.786e+01 2.362 0.018208 *
xcartaddtotalrs 7.089e-02 2.406e-03 29.465 < 2e-16 ***
xcartremove -5.810e+01 3.842e+01 -1.512 0.130598
xcardtremovetotal 4.299e+02 5.430e+01 7.917 3.09e-15 ***
xcardtremovetotalrs -7.004e-02 2.066e-02 -3.390 0.000705 ***
xproductviews 9.629e+00 9.405e-01 10.238 < 2e-16 ***
xuniqprodview -1.097e+01 1.080e+00 -10.159 < 2e-16 ***
xprodviewinrs 2.344e-04 4.456e-05 5.261 1.51e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1351 on 4174 degrees of freedom
Multiple R-squared: 0.7109, Adjusted R-squared: 0.7103
F-statistic: 1140 on 9 and 4174 DF, p-value: < 2.2e-16
And this summary has list of parameters like
f statistics check whether R squared is different from zero.
With reference to this model summary, we have Residual standard error as 1351, which should be as small as possible (logically with value 0 denotes perfect prediction). Where Multiple R squared as 0.7109 which denotes this model has nearly 71% prediction accuracy. We can see that xproductviews and xcartaddtotalrs have more impact on the product revenue. Here, 9.629 unit increase in product revenue explained by 1 unit increment in xproductviews.
Therefore, we can see product revenue may be majorly dependent on the total page views of product-page as well as total number of times the product is added to cart. Therefore the product revenue is largely proportional to the product-page views. We can assume here that, we can achieve increment on product transactional revenue on base of more numbers of page view. If you need to do this yourself in R, you can download R code + sample dataset. In the next blog post (Product revenue prediction with R – part 2), I will share how to improve our predictive model with R.
Want us to help you implement or analyze the data for your visitors. Contact us
Would you like to understand the value of predictive analysis when applied on web analytics data to help improve your understanding relationship between different variables? You may check out our Solution on performing predictive analysis on your web analytics tool data.





